Morphable models
One of the easiest and common approaches to face shape reconstruction are 3D morphable models (3DMM). For example, the FLAME head model is used left and right in research papers. Among recent works making use of 3DMM that I’ve seen, HRN demonstrates quite impressive results.
I’m not going to discuss in depth 3DMMs, how they work or how they’re built. Let’s just mention that with this approach, a 3D shape is reconstructed as a linear combination of basis components.
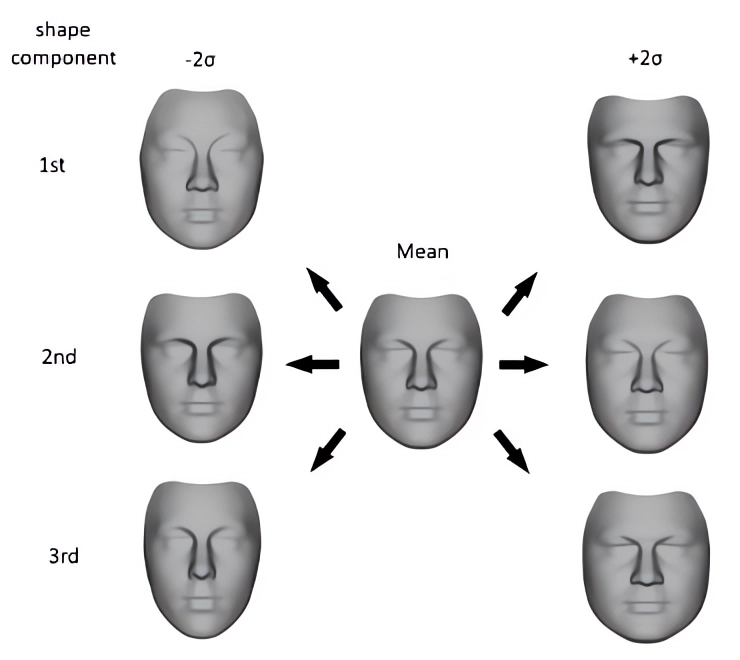
Figure 1: first components of a 3DMM
Score Distillation Sampling
Now what’s more interesting is how to reconstruct a head shape given some condition, like a photo or a text description. At ReadyPlayerMe, we predict morphable model’s weights from a single face image. One of the alternatives to that (less practical, but more fun) would be using pretrained diffusion model’s prior knowledge in image space, like it’s done in DreamFusion. The method introduced in this paper, Score Distillation Sampling (SDS) permits 3D model parameter tuning using a pretrained diffusion model.
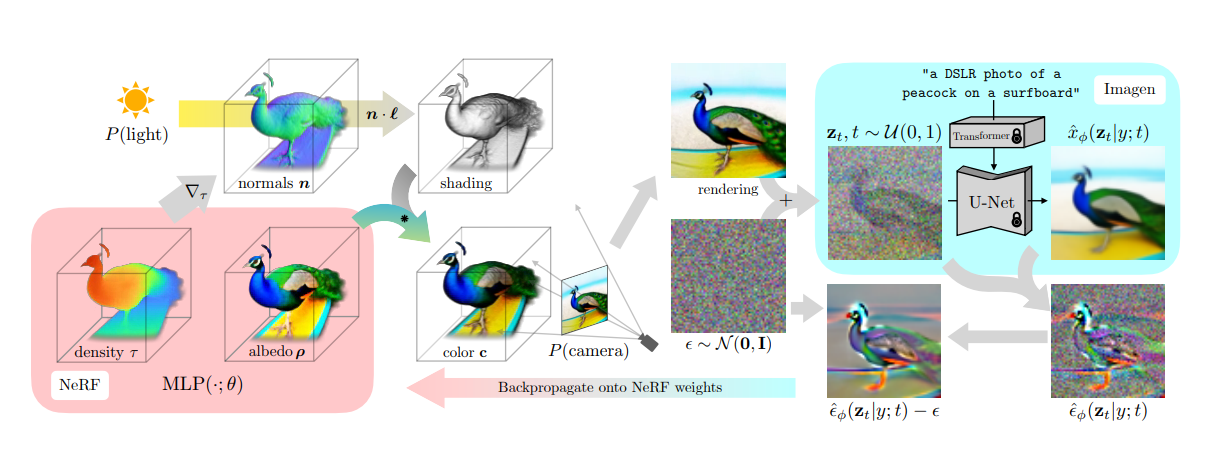
Figure 2: DreamFusion, SDS pipeline for NeRF
To be able to tune a 3D model, we must be able to compute gradients of the diffusion loss from latent space down to the parameters of the 3D model. Let’s take a look at the expression for those gradients:
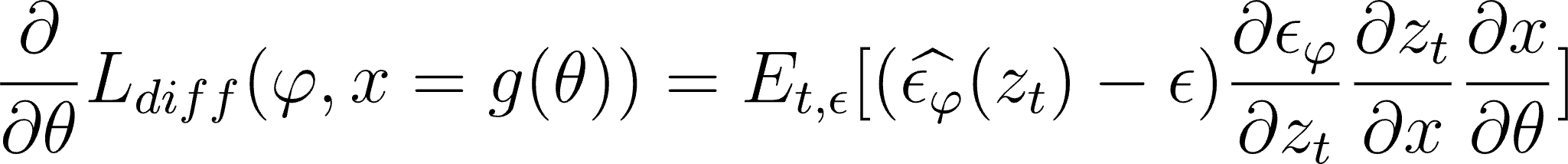
Where x = g(θ) is the render image generated with a 3D model with parameters θ. Noise ε is predicted by UNet (with parameters φ) from latents z after adding noise to them. Among the three derivatives to be used, the first one (UNet Jacobian) is heavy to compute and is proposed to be omitted. Considering that the latents derivative (corresponding to the encoder) is a constant, we get the following expression:
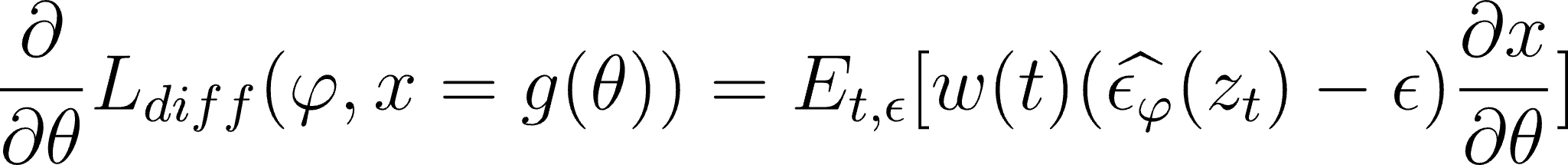
Now this looks way more usable. So we can compute gradients for 3D model parameters by just back-propagating the additional part, which is the difference between the noise added to the image latents and the noise predicted by the UNet. The rest is automatically computed thanks to torch autograd.
3DMM tuning
In the case of a 3D morphable head model, the parameter space is the vector of the model’s basis weights. I’ll take a custom, very simple head 3DMM, with 50 components, and iteratively tune its weights using some text description. One thing to keep in mind is that SDS brings instability, so clipping gradients will help in this case. Also, to prevent weights explosion I’ll add L2 regularization.
Here are some examples, with head model evolution and the text that’s being used as a condition for Stable Diffusion’s UNet.

Figure 3: From left to right: Winston Churchill, Scarlett Johansson, Barack Obama
Even with the small size of the 3DMM I’m using, I’d say the results look pretty recognizable. We could also create textures for those heads, tuning them directly in the UV space. Although this seems to produce noisier results.

Figure 4: Scarlett Johansson, texture generated with SDS
Implementation details
Here’s a pseudocode demonstrating how to implement SDS.
# get text embeddings for your prompt
text_embeddings = encode_prompt(prompt)
for _ in range(iterations):
# render 3D scene
render = render_scene()
# encode using SD VAE
latents = encode_image(render)
# We're omitting UNet gradients
with torch.no_grad():
# add noise to latents
noise = torch.randn_like(latents)
latents_noised = add_noise(latents, noise)
# predict noise with UNet
noise_pred = unet(latents_noised, t, text_embeddings)
# classifier free guidance from diffusers
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + \
guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute gradients
w = (1 - scheduler.alphas[t])
grad = w * (noise_pred - noise)
# back propagate
latents.backward(gradient=grad, retain_graph=True)