In this post, I want to revisit Score Samping Distillation (SDS) for 3D head synthesis. Having recently found this paper, I discovered several ideas on how to properly generate textures with SDS. In my previous post on this topic I was mentioning that it was particularly complicated to generate clean face textures.
Figure 1: Image from the paper: faceg2e pipeline
Geometry phase
First thing to notice is that the pipeline is split into two parts: geometry generation and then texture generation. Geometry is decoupled from texture in order not to produce textures with geometry details baked in them.
The first part is pretty much the same as I described in my previous post. 3DMM parameters are iteratively updated with a grey-scale render (all vertices assigned the same color) being fed into denoising unet. One thing different is scheduling timestamp to linearly decrease during the training.
Without proposed view-dependent prompts, I get something like this during the geometry phase:

Figure 2: From left to right: Scarlett Johansson, Barack Obama, Elon Musk, Leelee Sobieski
Texture phase
During the texture phase, we fix the geometry and tune the texture in the latent space of VAE decoder. In order not to produce cleaner textures, two types of supervision are proposed.
Depth supervision: use depth-controlnet, by passing to it depth-render of the mesh, to keep awareness of the geometry itself, separated from the texture. This is intended to get rid of geometric details baked into texture, and to “uphold geometry-texture alignment”.
Texture-prior: train a custom SD model on textures. This custom SD would help to get rid of light baked into textures, making use of learnt texture distribution.
First, I’m just gonna add the first type of supervision, by using a depth-controlnet. Instead of randomly initializing texture latents, I’ll use latents of some fixed texture for each training. Let’s see the results I get:
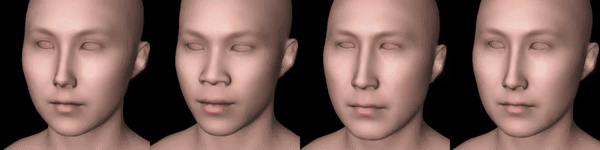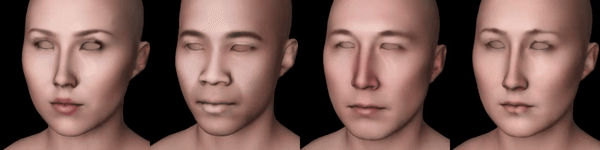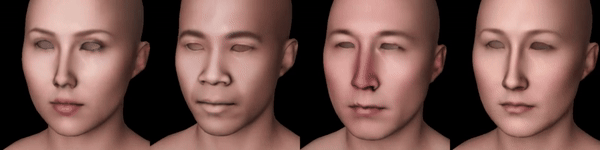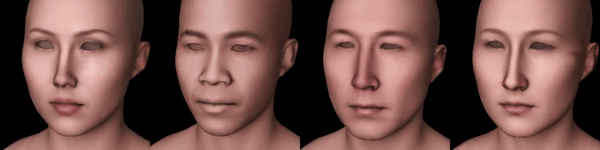
Figure 3: From left to right: Scarlett Johansson, Barack Obama, Elon Musk, Leelee Sobieski
Now, I’m gonna add something similar to the proposed texture-prior, but without having to train my own SD model. Instead, I will use a controlnet model trained on a pair of textures and canny edges in them. Passing a fixed control input to this controlnet, alongside with a prompt like “face texture,” I’ll pass its output to the denoising UNet and get a second SDS gradient tensor (additional to the one obtained with depth-controlnet).
Figure 4: From left to right: Scarlett Johansson, Barack Obama, Elon Musk, Leelee Sobieski
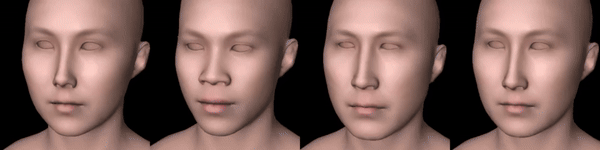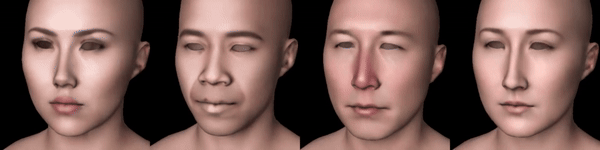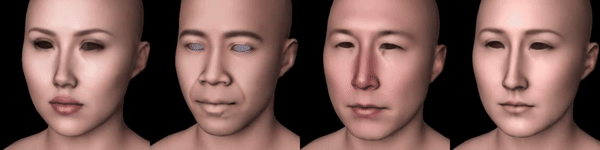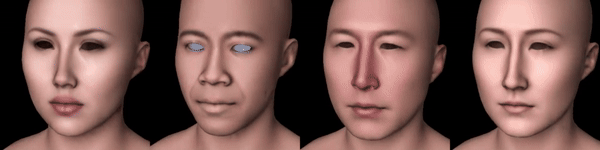
Notice how with the second type of supervision added, resulting textures have more even lighting.